Just Ask For Logprobs
LLM logprobs are a beautiful thing for researchers and hobbyists. You can use them to measure the model’s uncertainty. Or break ties. Or for model distillation.
Preventing the competitive disadvantage from the last use case is maybe the reason the latest GPT model, GPT-4, keeps its logprobs shyly hidden. People are understandably disappointed by this, with some resorting to querying the model many times at high temperature to get an estimate. But do we need the API at all? What if we can get the logprobs… just by asking?
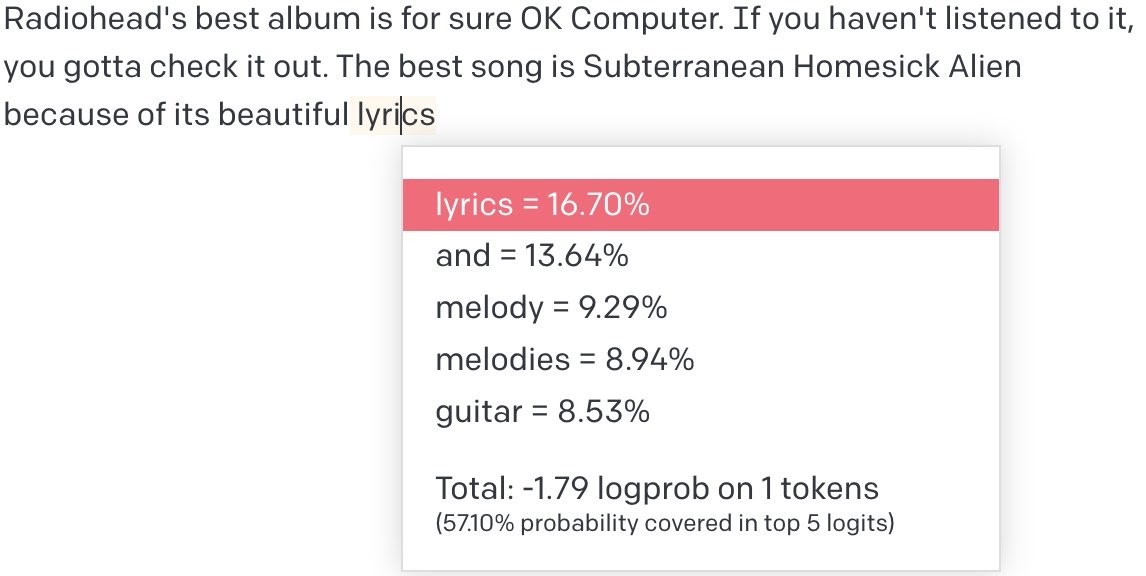

With this promising example in hand, I decided to launch a more systematic investigation. Since we have logprobs for GPT-3.5, can we match those logprobs without using the parameter? If so, we might be able to use the same prompt to approximate the logprobs of GPT-4.
Spoiler alert: it kind of worked but not really.
Choosing Data
I used examples from the test set of the Pile as I figured they wouldn’t be in the model’s training data. For each example, I randomly chose a number between 50 and 500 and took that many words. The examples range over code, patents, Wikipedia, and more.
Exfiltration Prompts
I figured few-shot was the way to go, so I first ran 11 Pile prompts through GPT-3.5 to get the real logprobs to act as examples. I used them for all three exfiltration prompts I tried.
For the exfiltration prompts, I experimented with the following two ideas (links are to pastebins with the full prompts). Nothing too flashy.
Analysis Details
- I ignored any examples where the output didn’t match the specs (5 words whose probabilities have a positive sum). This meant ignoring 5% of the examples for Prompt 1, 7.5% for Prompt 2.
- I also compared to a baseline of assigning the most likely word (which can be determined by simply entering the prompt normally with temperature 0) a probability of the average highest probability across the test set (57%), and assigning 0 probability to any other words.
Results
| Top 5 Overlap | Agreement Rate Lower Bound | Top 1 Match Rate | Top 1 Presence Rate | |
|---|---|---|---|---|
| 0 | 1.36782 | 0.262418 | 0.545977 | 0.649425 |
| 1 | 1.4152 | 0.296105 | 0.561404 | 0.672515 |
| 2 | 1 | 0.32299 | 1 | 1 |
Here are the results. First row is first prompt, second is second. Now I’ll explain what the metrics mean.
Let’s start with the most complicated one: Agreement Rate Lower Bound. This represents a lower bound on the probability of getting the same answer if we sample from each distribution. Here’s a numerical example. Let’s say the “true” probabilities are: {‘A’: 0.5, ‘B’: 0.2, ‘C’: 0.1, ‘D’: 0.05, ‘E’: 0.05}
That adds to 0.9 which leaves 0.1 for the field. (Note: the API provides logprobs only for the most likely 5 words.)
Now let’s say the exfiltrated probabilities are: {‘A’: 0.5, ‘Z’: 0.3, ‘C’: 0.02, ‘Y’: 0.01, ‘X’: 0.01}
The probability of a match is the sum over all the words in p_true of p_true[word] * p_predicted[word] = 0.5 * 0.5 + 0.1 * 0.02 = 0.252
The number in the table is the average across all test cases. This goes for all the other metrics too.
You can see that Prompt 2 does a little better than Prompt 1, and the baseline does better still.
Why do I say it’s a lower bound? Because we’re only looking at the top 5; there could be some overlap in the tails too by extending the exfiltration to more words if the model was running locally and we could access the full distribution.
Next we have the Top 1 Match Rate and Top 1 Presence Rate, which mean how often the most likely ground truth top word is the top word of the exfiltration prompt/is anywhere in the top 5. Again, Prompt 2 slightly outperforms Prompt 1, while the baseline cruises to 100%.
Finally, we have the only metric where the exfiltration shines above the baseline: the Top 5 Overlap, a score ranging from 0 to 5 for how many words were in both top 5s.
Closing Thoughts
A 1.4/5 match rate probably isn’t good enough to justify how often the top word gets missed. Still, it’s something! Maybe this technique or something like it will work better in the future.
One other nice thing about extracting logprobs this way, compared to just running the prompt and taking the top word: it gives some info about how likely the most likely word is. AKA how confident the model is. Evidence: on examples where the top word has probability < 0.9, the exfiltration top word prob is 0.64. Whereas when the top word has probability > 0.9, the exfiltration top word prob jumps to 0.80.
It’s not clear how much this all transfers to GPT4. I imagine it mostly does though.
Code for reproducing this is available at the Github repo.